


隨著人工智慧的爆發,AI 模型的算力與記憶體之間的矛盾日益浮現。Google Research 於近期發表的全新壓縮演算法「TurboQuant」,以驚人的數據為這場技術博弈投下了震撼彈。以下將從記憶體困境、TurboQuant 的核心技術,到其現實挑戰與未來展望進行完整介紹。
⭐為何 AI 的記憶體需求如此巨大?⭐
當 AI 模型在閱讀或生成文字時,它不會將文字視為字母,而是轉化為包含數千個數字的「向量」。在對話過程中,AI 需要記住你之前說過的所有內容,為此它會生成一個名為 KV Cache(鍵值緩存) 的暫存區。 你可以將 KV Cache 想像成 AI 在開卷考試時寫下的「重點小抄」。傳統上,為了追求高精確度,業界習慣使用高位元的浮點數(如 16-bit 的 FP16 或 BF16)來儲存這些數據。但當對話文本越來越長,這張小抄就會像黑洞一樣,無止盡地吞噬掉極度昂貴的記憶體空間。

⭐硬體核心為何變成一堵「記憶體牆」?⭐
在現代 AI 運作中,遇到了一個被稱為「記憶體牆(Memory Wall)」的物理與架構瓶頸。簡單來說,GPU 的運算速度就像是一輛極速狂飆的法拉利跑車,但記憶體的傳輸頻寬卻像是一條極窄的單行道巷子。 即使處理器的算力再強,只要數據來不及從記憶體搬運過來,最強的晶片也只能排隊空轉。這種算力與記憶體傳輸速度之間的不匹配,成為了限制 AI 發展的最脆弱環節。

⭐目前記憶體與 GPU 的嚴峻現況⭐
由於上述的記憶體牆與龐大需求,目前的硬體市場呈現出「貴且稀少」的極端情況。為了提供更高的傳輸頻寬,AI 伺服器高度依賴 HBM(高頻寬記憶體),這導致 HBM 價格居高不下且供不應求。企業為了運行大型模型,往往需要支付天價購買如 NVIDIA H100 等頂級晶片來堆疊記憶體容量。這種「單純靠硬體堆料」的商業模式,讓 AI 的運行成本變得極度高昂。
⭐TurboQuant 是什麼?如何解決記憶體問題?⭐
TurboQuant 是 Google Research 提出的一項「免重新訓練」的即時向量量化壓縮演算法。它能在不損失精度的前提下,將 KV Cache 從原本的 16-bit 極限壓縮到約 3-bit,達成 6倍的空間節省,並在特定硬體上提升最高 8倍的運算速度。

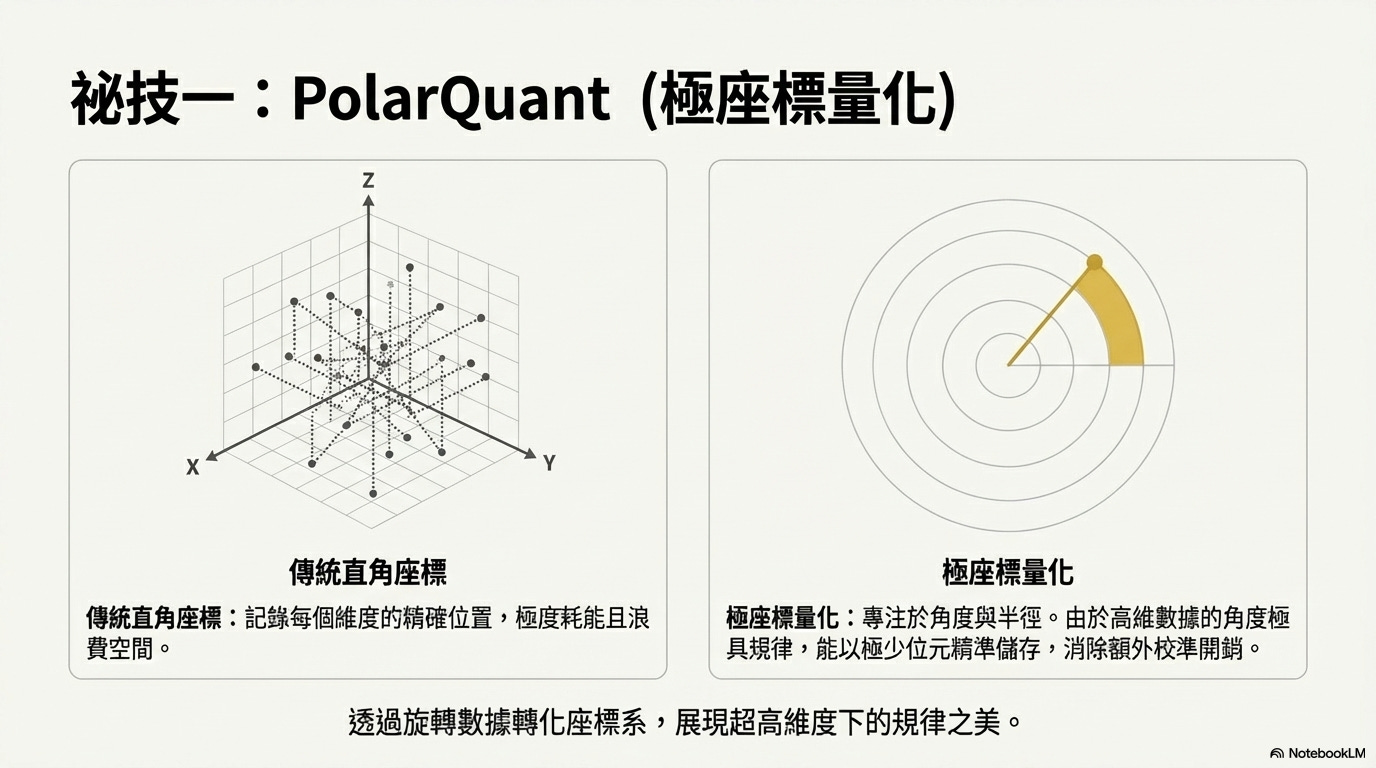
第一步:PolarQuant(極座標量化) 傳統儲存向量是使用直角座標(X, Y網格),而 PolarQuant 透過隨機旋轉數據,將其轉換為「極座標(半徑與角度)」。在超高維度下,角度的分布極具規律,這讓系統能以極少的位元數精準儲存數據,同時完全消除了傳統量化所需的額外校準記憶體開銷。
第二步:QJL 修正器(量化約翰遜-林登斯特勞斯變換) 壓縮後無可避免會有微小誤差。QJL 是一個強大的數學機制,它僅用 1 個位元(1-bit) 的微小成本,就能將這些誤差精準校正,確保模型判斷時保持「零偏差」。
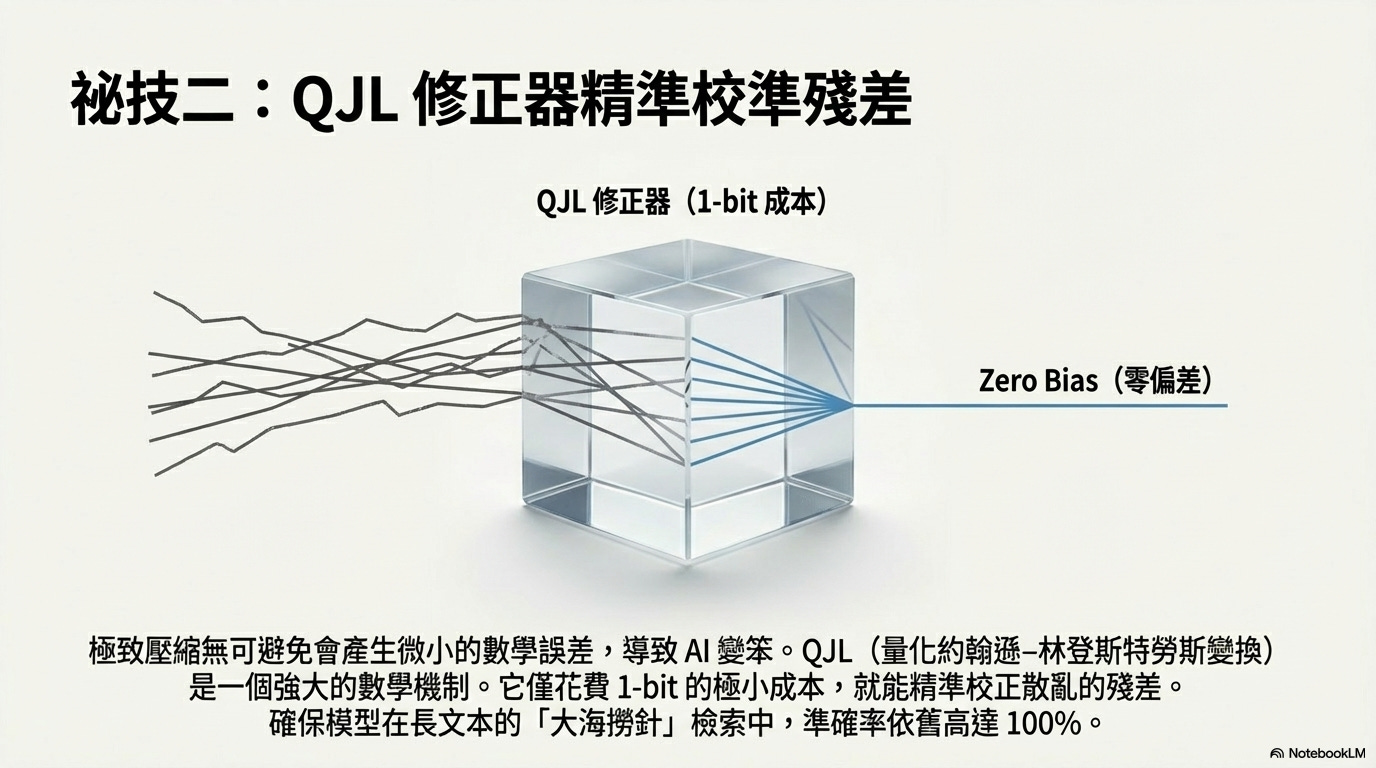
實測證明,壓縮至 3-bit 的模型不僅在長文本中擁有 100% 的「大海撈針」檢索準確率,其注意力保真度也高達 99.5%,達到了零精度損失的境界。

⭐現實與理想的落差及壞處挑戰⭐
儘管 TurboQuant 看似完美,但目前仍面臨一些現實落差與挑戰:
過度壓縮會變笨:雖然 3-bit 是完美的平衡點,但若激進地壓縮至 2-bit,模型的首選準確率會大幅下降至 66%,AI 會開始搞錯重點並影響回答品質。
硬體依賴性:目前要發揮其宣稱的「最高 8 倍加速」極致效率,仍需要依賴特定的頂級硬體架構,普及到所有設備的最佳化還需時間。
短期產業震盪:由於軟體能省下 6 倍記憶體,雲端大廠對高階硬體的採購預期大幅下修,引發了市場對記憶體廠(如美光等)獲利的恐慌與股價震盪。
結文斯悖論(Jevons Paradox):這是一個潛在的長期「壞處」或現象。雖然單個模型的記憶體負擔減輕了,但當 AI 變得便宜,開發者會塞入更龐大的資料、追求更複雜的推理。長期下來,全球對記憶體的總體需求量反而可能會因為應用爆發而大幅回升。
⭐它是「空間效率」的革命,而非「傳輸物理」的革命⭐
目前的記憶體牆有兩個維度:容量與頻寬。
容量問題:這部分 TurboQuant 確實「解決」了。原本 80GB 的 VRAM 只能跑一個特定長度的模型,現在透過 6 倍壓縮,同樣的硬體能跑原本 6 倍長的對話。這對降低「成本」非常有感。
頻寬問題(物理牆):數據從記憶體搬到晶片的速度受限於電子物理特性。雖然 TurboQuant 宣稱有 8 倍加速,那是因為它把數據縮得很小,搬運次數變少了。但只要模型變得更巨大,這道「窄巷」依然在那裡,只是法拉利換成更小的賽車跑得更勤快而已。
歷史證明:當資源的使用效率提升時,人類對該資源的總需求量反而會爆炸。
當你發現原本只能記住 1 萬字的 AI,現在能記住 100 萬字且更便宜時,開發者會毫不猶豫地開發需要 1000 萬字記憶的應用。因此,對 HBM 這種高階記憶體的依賴,可能只是從「維持現狀」變成「支撐更瘋狂的應用」。因此我不認為會影響記憶體產業,甚至需求量更大。
⭐理想與現實的「硬體時差」⭐
TurboQuant 的數學很完美,但它需要硬體單元的高度優化。簡單說就像有一套全新的速記法(TurboQuant),可以寫得飛快,但目前全世界只有 Google 特製的筆能寫出這種字。如果你的設備缺乏專門針對 3-bit 或極座標運算的硬體指令集,那麼在軟體層面的模擬反而會消耗額外的算力,導致「省了空間卻變慢了」。這種硬體迭代的時差,通常需要 2 到 3 年才能填平。
⭐TurboQuant 解決不了什麼?(它無法完全解決的嚴峻現況)⭐
只影響推理,不影響訓練。訓練時最大的記憶體消耗是模型權重 + 激活值 + 優化器狀態,KV Cache 只占很小一部分。HBM 短缺的主因是訓練大模型(Blackwell、Rubin 等新一代 GPU 依然瘋狂搶 HBM),TurboQuant 完全碰不到這塊。
模型權重本身還是需要 HBM。即使 KV Cache 壓縮 6 倍,權重還是原本的大小(除非另外做 4-bit / 2-bit 權重量化)。
硬體供應鏈短期內不會因為這篇論文就鬆綁。SK Hynix、Samsung、Micron 的 HBM 產能已經被預訂到 2027 年。記憶體晶圓短缺預計持續到 2030 年(這是結構性問題,不是單一演算法能解決)。
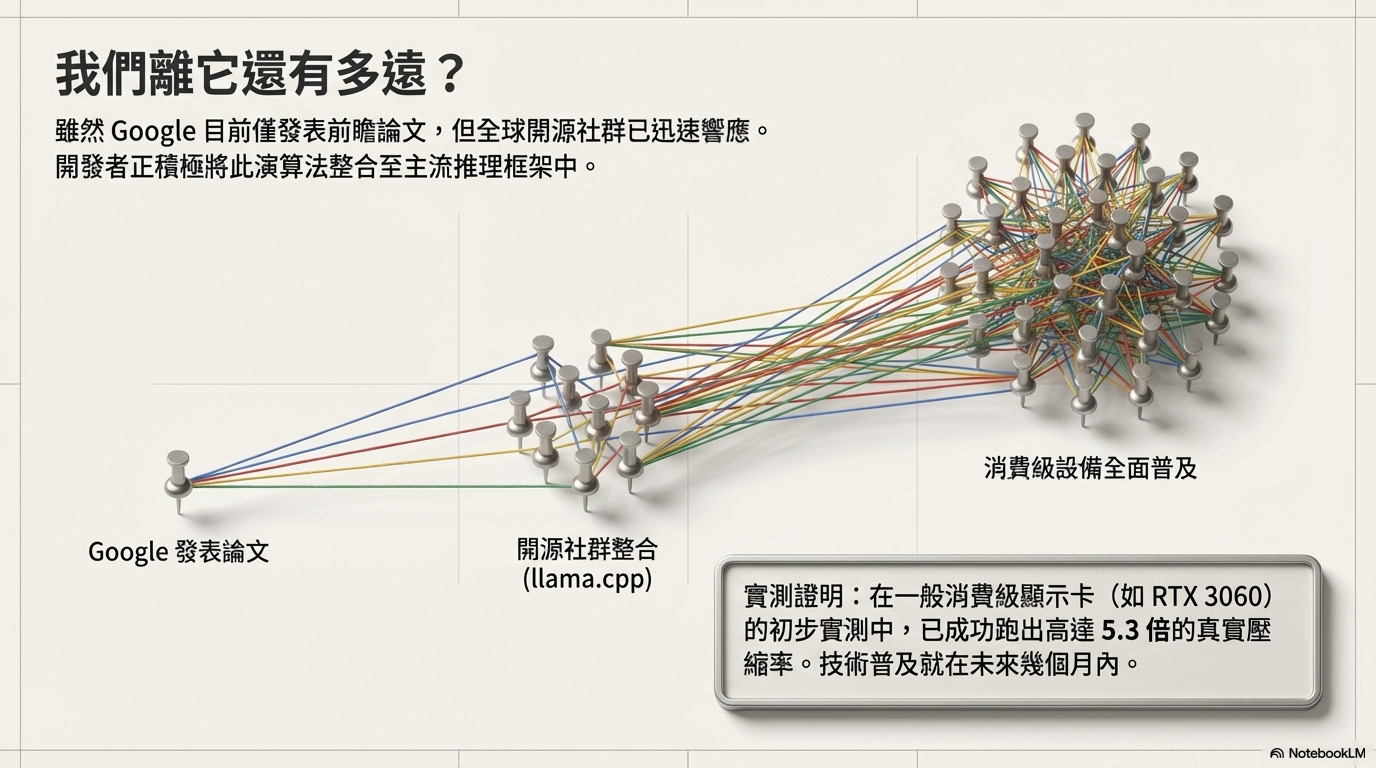
目前還在早期階段:論文剛發表 2 天,Google 還沒釋出官方程式碼。雖然社群已經有人在 llama.cpp 做出 CPU / Apple Silicon 原型(壓縮率接近論文),但 CUDA / vLLM 正式整合還要幾週到幾個月。生產環境要真正落地,還需要更多測試與優化。
⭐此技術還有多遠?⭐
TurboQuant 的正式論文預計在 2026 年 4 月的 ICLR 大會上發表,目前 Google 尚未推出官方的產品級程式碼,仍處於研究階段。
不過,我們離它並不遙遠。目前全球開源社群極度活躍,許多開發者已經開始在 llama.cpp、vLLM、Apple MLX 等主流框架中實作原型,甚至在一般家用電腦(如 RTX 3060)上成功驗證了近 5 倍的記憶體壓縮效果。預計在未來幾個月內,這項技術就會被廣泛整合進各式開源工具中。
總結來說,TurboQuant 不僅是一項軟體技術的勝利,更重塑了 AI 的商業邏輯。它將讓未來的手機與一般筆電都能流暢運行龐大的本地 AI,讓 AI 真正走向不受硬體極限束縛的普惠時代。
TurboQuant 是「軟體效率革命」的重要一步,它會降低對硬體的依賴程度,讓 AI 發展速度不會被 HBM 短缺完全卡死。但它不是萬靈丹,而是與硬體升級(更多 HBM 產能)、其他演算法(MoE、推測解碼、混合精度)一起協同作用。

原本對於這段描述不太能理解 "TurboQuant 的數學很完美,但它需要硬體單元的高度優化。簡單說就像有一套全新的速記法(TurboQuant),可以寫得飛快,但目前全世界只有 Google 特製的筆能寫出這種字。如果你的設備缺乏專門針對 3-bit 或極座標運算的硬體指令集", 所以問了Gemini.
下列的說明會較精確一點:
1. 「硬體單元高度優化」:正確
量化技術的核心在於將浮點數(FP16/BF16)壓縮成整數(INT4/INT3)。然而,現代 GPU(如 NVIDIA 的 Tensor Cores)主要是為 4、8、16 位元設計的。
3-bit 的尷尬:電腦通常以 2 的次方處理數據。3-bit 並非標準單位,硬體通常無法直接讀取。
計算開銷:如果硬體沒有專門的指令集,GPU 必須花額外的力氣把 3-bit 「解壓」回高位元才能運算,這反而可能讓速度變慢。
2. 「Google 特製的筆」:半準確(具體硬體而定)
這個比喻很好,但目前在 AI 領域,這支「筆」通常指的不只是 Google 的 TPU,更多時候是指 **NVIDIA 最新架構(如 Blackwell 或 Hopper)**中的專用引擎,或是專門寫給特定 GPU 的 CUDA Kernel。
如果你的 GPU 只有舊款的運算單元,就像用粗毛筆去寫精細的速記字,完全發揮不出威力。
3. 「極座標運算」:需要修正
這是描述中最需要注意的地方。目前的低位元量化技術(如 GPTQ, AWQ, 或相關變體)主要基於線性縮放(Linear Scaling)或統計分布,較少直接提到「極座標運算」。
可能混淆了:你指的可能是某些基於「向量旋轉」或「複數空間」的特殊編碼技術,或者是像 Logarithmic Quantization(對數量化)。在標準的 TurboQuant 討論中,重點通常在於非對稱量化與位元封裝(Bit-packing)。
謝謝無私分享,
提高對AI發展的認知。